
C++学习
智能指针
unique_ptr
这个智能指针是独占指针,私家车,给一块内存空间“加锁”,只有这个能调用。
unique_ptr可以转移不能赋值
注意声明用法;
get()函数是可以将unique_ptr的地址赋值给别人,返回unique_ptr的地址;虽然unique_ptr有独占性但是还是可以用这种方法操作
realse()函数返回unique_ptr的地址,但是会将unique_ptr的指针指向空,但是不释放内存空间
reset()函数unique_ptr的指针指向空,并且释放内存空间
int main()
{
int* intP = new int(10);
//声明智能指针
std::unique_ptr<int>intPtr{std::make_unique<int>(100)};
std::unique_ptr<int>intPtr1{ };
//声明智能指针数组
std::unique_ptr<int[]>intPtrarr{};
std::cout << *intP << std::endl;
std::cout << *intPtr << std::endl;
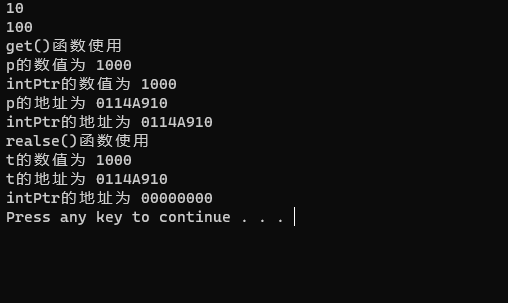
std::cout << "get()函数使用" << std::endl;
//get()
int* p = intPtr.get();
*p = 1000;
std::cout << "realse()函数使用" << std::endl;
//release()
int* t = intPtr.release();
std::cout << "t的数值为 " << *t << std::endl;
std::cout << "t的地址为 " << t << std::endl;
std::cout << "intPtr的地址为 " << intPtr << std::endl;
//reset()
intPtr.reset();
system("pause");
return 0;
}
move()函数
int main()
{
int* intP = new int(10);
//声明智能指针
std::unique_ptr<int>intPtr{std::make_unique<int>(100)};
std::unique_ptr<int>intPtr1{ };
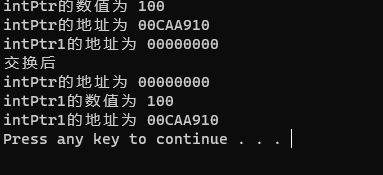
std::cout << "intPtr的数值为 " << *intPtr << std::endl;
std::cout << "intPtr的地址为 " << intPtr << std::endl;
std::cout << "intPtr1的地址为 " << intPtr1 << std::endl;
std::cout << "交换后 " << std::endl;
intPtr1 = std::move(intPtr);
std::cout << "intPtr的地址为 " << intPtr << std::endl;
std::cout << "intPtr1的数值为 " << *intPtr1 << std::endl;
std::cout << "intPtr1的地址为 " << intPtr1 << std::endl;
system("pause");
return 0;
}
shared_ptr
shared_ptr具有共享性。可以有多个shared_ptr指向同一块内存空间,但是只有最后一个shared_ptr释放的时候才会释放掉这块内存空间。shared_ptr会保存当前地址有多少个智能指针调用
use.cout()可以统计当前内存空间有多少个指针调用
unique()返回一个bool类型的变量指示该指针是否是唯一的
reset()用法和unique_ptr不一样,这里是将指针设置为null,但是如果不是最后一个的话是不会释放内存空间的。
int main()
{
int* intP = new int(10);
std::shared_ptr<int>ptrA{ std::make_shared<int>(100) };
std::shared_ptr<int>ptrB{ };
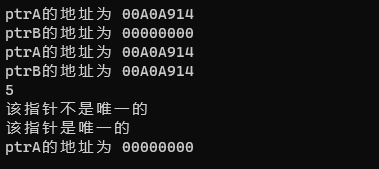
std::cout << "ptrA的地址为 " << ptrA << std::endl;
std::cout << "ptrB的地址为 " << ptrB << std::endl;
ptrB = ptrA;
std::cout << "ptrA的地址为 " << ptrA << std::endl;
std::cout << "ptrB的地址为 " << ptrB << std::endl;
std::shared_ptr<int>ptrE{ };
std::shared_ptr<int>ptrC{ };
std::shared_ptr<int>ptrD{ };
ptrE = ptrA;
ptrD = ptrA;
ptrC = ptrA;
std::cout << ptrB.use_count() << std::endl;
if (ptrA.unique())
{
std::cout << "该指针是唯一的" << std::endl;
}
else
{
std::cout << "该指针不是唯一的" << std::endl;
}
std::shared_ptr<int>ptr123{ std::make_shared<int>(1000) };
if (ptr123.unique())
{
std::cout << "该指针是唯一的" << std::endl;
}
else
{
std::cout << "该指针不是唯一的" << std::endl;
}
ptrA.reset();
std::cout << "ptrA的地址为 " << ptrA << std::endl;
return 0;
}
Union联合体
函数返回
第一种最简单的返回 函数运行在栈上,函数中生成的临时变量Role,在函数运行结束后会销毁。main函数中使用的Role实际上是临时变量的复制,将栈上的数据完完整整复制了一个Role过来。这样太占内存空间了
typedef struct Role
{
char* name;
int hp;
int mp;
int maxhp;
int maxmp;
int lv;
}*PRole,ROLE;
Role create(const char* s, int hp, int mp)
{
Role t = { cstr(s),hp,mp,hp,mp,1 };
return t;
}
int main()
{
Role a = create("Niko", 100, 50);
std::cout << a.name << std::endl;
std::cout << a.hp << std::endl;
std::cout << a.mp << std::endl;
std::cout << a.maxhp << std::endl;
std::cout << a.maxmp << std::endl;
std::cout << a.lv << std::endl;
}那如果我们使用指针呢?直接返回一个指针,这样就不用在生成一个Role了
这样我们生成Role的方式变成了new,生成在堆区。
PRole create(const char* s, int hp, int mp)
{
PRole t = new Role{ cstr(s),hp,mp,hp,mp,1 };
return t;
}
int main()
{
Role* a = create("Niko", 100, 50);
std::cout << a->name << std::endl;
std::cout << a->hp << std::endl;
std::cout << a->mp << std::endl;
std::cout << a->maxhp << std::endl;
std::cout << a->maxmp << std::endl;
std::cout << a->lv << std::endl;
}还有一种方法返回引用,返回的是地址。
Role& create(const char* s, int hp, int mp)
{
PRole t = new Role{ cstr(s),hp,mp,hp,mp,1 };
return *t;
}
int main()
{
Role a = create("Niko", 100, 50);
std::cout << a.name << std::endl;
std::cout << a.hp << std::endl;
std::cout << a.mp << std::endl;
std::cout << a.maxhp << std::endl;
std::cout << a.maxmp << std::endl;
std::cout << a.lv << std::endl;
}不定量参数
上次学的不定量参数是main函数中使用的 int main(int cnt,chararc[])
这里的不定量参数是运用到函数中的
教的很简单相当于一套模板固定搭配使用
int average(int cnt, ...)
{
va_list(arg);
//char *arg
//arg 的使用会自增,这里的int是告诉他要用int类型去读取
va_start(arg, cnt);
int sum = 0;
for (int i = 0; i < cnt; i++)
{
sum += va_arg(arg, int);
}
va_end(arg);
return sum / cnt;
}
void main()
{
std::cout << average(5,1,2,3,4,5) << std::endl;
}左值右值
这里可以回头看看之前的课程
函数指针
函数的本质其实就是一连串的内存地址
函数名其实就是函数指针的变量名
这里我们给*padd这个指针 指向了add函数
函数模板重载 例外
这是因为传入的是地址,拿A和B的地址在进行比较
template<typename T>
T ave(T a, T b)
{
return a > b ? a : b;
}
int main()
{
int a = 101;
int b = 110;
int c = *ave(&a, &b);
std::cout << c << std::endl;
return 0;
}
定义一种例外情况就好
实际上这个template<>也可以删除掉,编译器肯定是先套其他有的函数最后才回去套模板
执行顺序函数重载一定大于函数模板
template<>
int * ave(int * a, int * b)
{
return *a > *b ? a : b;
}
int main()
{
int a = 101;
int b = 110;
int c = *ave(&a, &b);
std::cout << c << std::endl;
return 0;
}函数模板依旧可以发生重载
template<typename T>
T ave(T a, T b)
{
return (a + b) / 2;
}
template<typename T>
T ave(T a, T b,T c)
{
return (a + b+c) / 2;
}
int main()
{
int a = 101;
int b = 110;
int c = 220;
std::cout << ave(a,b) << std::endl;
std::cout << ave(a, b,c) << std::endl;
return 0;
}
auto->decltype
auto
先简单说下auto的用法 自动类型推导 关键是typeid(a).name()函数可以显示出类型名 包括函数返回值也可以使用auto自动推导
int main()
{
auto a = 20;
auto b = 10.1;
auto c = 'c';
auto d = &a;
std::cout << typeid(a).name() << std::endl;
std::cout << typeid(b).name() << std::endl;
std::cout << typeid(c).name() << std::endl;
std::cout << typeid(d).name() << std::endl;
}

但是auto有缺点
不能保留const类型的属性
优先推导为值类型而不是引用

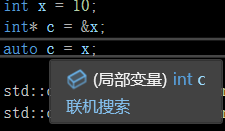
->拖尾函数
看下面这个例子
首先这段代码是正常执行的
auto bigger(int a, int b)
{
return a > b ? a : b;
}
int main()
{
int a = 100;
int b = 10;
auto x = bigger(a, b);
std::cout << typeid(x).name() << std::endl;
std::cout << x<< std::endl;
}
但是如果我们想要节省内存空间 想用引用传到a和b的值进入函数 并且之后修改值 可以看到出现报错了
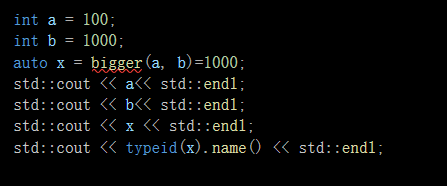
这是因为上面的缺点2 如何解决? 我们知道要返回a或者b的地址才能进行修改,那么就是int&,所以但是由于缺点2不能返回引用所以我们使用->这个拖尾巴
auto bigger(int& a, int &b)->int&
{
return a > b ? a : b;
}这相当于我们强制其达到这种目的
decltype
高级版本的auto
int a=10;
unsigned int b = 10;
decltype(a - b)x;
const int a1 = 10;
decltype(a1)x1=100;
int& a2 = a;
decltype(a2)x2=a2;
int* a3 = &a;
decltype(a3)x3;x自动推导为unsigned int. x1为const int 。 x2为int& . x3为int*
可以看到其完美解决了auto的缺点 但是auto和decltype有一点大区别 上面使用auto 会自动得到add函数的值给x1。 但是下面的x2指示帮你定义了x2的类型 这里不需要参数 直接给add让他自动推导就行了
auto x1 = add(10, 10);
decltype(add(10, 10))x2;decltype得到数据类型有三原则
是否经历运算 如果有运算那么看运算结果是否有固定的内存地址(左值),如果有那么他就是有一你用
没有固定的内存地址 那么推导出来的类型就是该结果的类型
使用函数结果来推导时 函数返回什么结果decltype得到的就是什么结果 注意decltype()内的函数并不会真的运行给其赋值
int a = 10;
int b = 100;
int* pa = &a;
//a-b是运算 a-b是临时计算的变量 没有固定内存地址的数值 所以x就是int类型的值
decltype(a - b)x;
//*号也是运算符 *pa是指针有固定的内存地址 所以x1是int&
decltype(*pa)x1=a;
//[]这个也是运算符 同上
decltype(pa[0])x2=a;可以利用auto解决上面的拖尾函数问题 a和b都是左值有固定的内存地址所以返回的是 int&
auto bigger(int& a, int &b)->decltype(a > b ? a : b)
{
return a > b ? a : b;
}在C++新特性中这种写法变成了
decltype(auto) bigger(int& a, int &b)
{
return a > b ? a : b;
}目前auto-decltype只需要了解 主要是和函数模板结合起来
int main()
{
int a = 10;;
//先输出a在输出a++ 临时变量 所以x1是int
decltype(a++)x1;
//++a是有内存地址的所以x2 是int&
decltype(++a)x2=a;
std::cout << typeid(x1).name() << std::endl;
std::cout << typeid(x2).name() << std::endl;
}推断函数模板返回类型
static和incline
局部static只有局部可以访问 全局static哪里都可以访问 如图x在main函数中不能直接访问
内存中是和全局变量存放在一起的 生命周期和全局静态变量一样

static int xx = 100;
int add(int a, int b)
{
static int x;
x++;
xx++;
std::cout << x << std::endl;
return a + b;
}
int main()
{
add(1, 1);
add(1, 1);
add(1, 1);
std::cout << xx << std::endl;
return 0;
}
内联函数 关键字inline
作用 加快运行速度 提升效率
内联的意思是直接把内联函数的代码复制到调用的地方 减少函数调用的开销 成本是程序变大 函数被调用多次则复制多次
c++17开始改变了对inline的定义
静态成员函数是可以多次编译的 目前了解这么多吧
extern关键字
C语言不支持函数重载
C++如何调用C语言的代码? 例如C++的源文件是c.c,头文件声明是c.h。 c++源文件是c++.cpp,头文件是c++.h
那么我们在想在cpp文件中使用.c文件中的函数需要在c++.h的头文件声明中加上extern "C" 关键字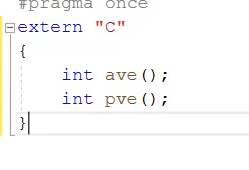
或者直接将用关键字加载头文件
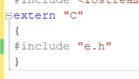
但是.c文件如何调用C++的函数呢?
我们也可以使用extern关键字 在.CPP文件中 告诉编译器 这个函数要用C风格来编写 这样就可以
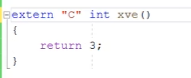
但是如果在c.h头文件声明加上关机键字则不行。在c.h中加上extern关键字,c++.cpp也要包含这个c.h,c.c也包含同一个头文件。但是C语言中是没有extern这个写法的。
还有一种方法

像ifdef__cplusplus #endif 这串声明 在cpp中是存在的,在.c中是不存在的.
如果在C++环境下呢 会把这串函数声明为extern "C"。 在Cpp下这串声明是有加了extern的在.c下是没有的
注意 如果声明函数为C语言风格,那么将不支持函数重载
