
C++核心 DAY2
C++ 核心DAY2
封装
简单的类定义 像这里的m_r就属于属性, 下面的函数是行为
#include "iostream"
using namespace std;
#define pi 3.14
class circul
{
public:
int m_r;
double get()
{
return 2*pi*m_r;
}
};
class student
{
public:
string name;
int num;
void show()
{
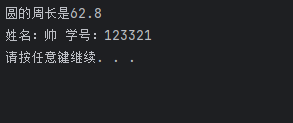
cout<<"姓名:"<<name<<" 学号:"<<num<<endl;
}
};
int main()
{
circul c;
c.m_r=10;
cout<<"圆的周长是"<<c.get()<<endl;
student s;
s.name="帅";
s.num=123321;
s.show();
system("pause");
return 0;
}
类的定义有三种权限
- 公共权限 谁都可以访问
- 保护权限 类内可访问,类外不可访问
- 私有权限 类内可访问,类外不可访问
保护权限和私有权限的区别要到继承才能学习到
可以这样理解 名字大家都知道 车可以借给别人 但是银行卡密码只能自己知道
class person
{
public:
string name;
protected:
string che;
private:
int password;
};
函数外根本访问不到车和密码
struct和class的区别
class的默认权限是私有,struct是公有
将成员属性设置为私有
这是类的一个很重要的作用 自己控制读写权限
这里可以看出把所有属性放到private权限,然后自己定义public权限内的函数怎么操作,便可以控制读写权限
例如:你只想读,那就只写读函数;
还有个有点是可以检测数据的有效性 这里是输入的age是否合法可以直接在类里面判断实现
class person
{
public:
void setname(string m_name)
{
name=m_name;
}
string getname()
{
return name;
}
int getage()
{
return age;
}
void setage(int m_age)
{
if(m_age<0||m_age>150) cout<<"WTF"<<endl;
else age=m_age;
}
void setlover(string m_lover)
{
lover=m_lover;
}
private:
string name;//名字 可读可写
string lover;//情人 只写
int age;//年龄
};
int main()
{
person p;
p.setname("shuai");
p.setage(23);
p.setlover("mei");
cout<<p.getname()<<endl;
cout<<p.getage()<<endl;
system("pause");
return 0;
}
两个黑马实现案例
案例一
class cube
{
public:
void setl(int l)
{
m_l=l;
}
int getl()
{
return m_l;
}
void seth(int h)
{
m_h=h;
}
int geth()
{
return m_h;
}
void setw(int w)
{
m_w=w;
}
int getw()
{
return m_w;
}
int gets()
{
return 2*m_l*m_h+2*m_l*m_w+2*m_h*m_w;
}
int getv()
{
return m_l*m_h*m_w;
}
// bool issame(cube c)
// {
// if(c.m_l==m_l&&c.m_h==m_h&&c.m_w==m_w) return 1;
// return 0;
// }
private:
int m_l,m_h,m_w;
};
bool issame(cube c1,cube c2)
{
if(c1.getl()==c2.getl()&&c1.geth()==c2.geth()&&c1.getw()==c2.getw()) return 1;
return 0;
}
int main()
{
cube c;
c.setl(1);c.setw(2);c.seth(3);
cout<<c.getl()<<" "<<c.getw()<<" "<<c.geth()<<endl;
cube a;
a.setl(1);a.setw(21);a.seth(3);
if(issame(a,c))
cout<<"相等"<<endl;
else cout<<"不相等"<<endl;
system("pause");
return 0;
}
案例二
这是使用类的好处可以实现==封装==
将头文件和源文件分开放 之后只需要在主文件内引入头文件就可以
这是test2.cpp的内容 注意这里头文件记得导入
#include <iostream>
#include "string"
#include "circul.h"
using namespace std;
int main()
{
point q;
q.setx(1);q.sety(1);
cout<<q.getx()<<" "<<q.gety()<<endl;
circul a;
a.setr(1);
point z;
z.setx(0);z.sety(0);
a.setp(z);
cout<<a.getp_x()<<" "<<a.getp_y()<<" "<<a.getr()<<endl;
a.where(q);
system("pause");
return 0;
}
这是point.h的内容 头文件记得写 ==#pragma once== 这是避免重复导入头文件
#pragma once
#include "iostream"
#include "string"
using namespace std;
class point
{
public:
void setx(int m_x);
void sety(int m_y);
int getx();
int gety();
private:
int x,y;
};
这是circul.h
#pragma once
#include "iostream"
#include "point.h"
#include "string"
using namespace std;
class circul
{
public:
void setr(int m_r);
int getr();
void setp(point m_p);
int getp_x();
int getp_y();
void where(point q);
private:
point p;
int r;
};
可以看到封装好的头文件删除掉了所有的函数实现
void point::setx(int m_x)
{
x=m_x;
}
void point::sety(int m_y)
{
y=m_y;
}
int point::getx()
{
return x;
}
int point::gety()
{
return y;
}
//下面是circul.cpp
void circul::setr(int m_r)
{
r=m_r;
}
int circul::getr()
{
return r;
}
void circul::setp(point m_p)
{
p=m_p;
}
int circul::getp_x()
{
return p.getx();
}
int circul::getp_y()
{
return p.gety();
}
void circul::where(point q)
{
int dis=(q.getx()-p.getx())*(q.getx()-p.getx())+(q.gety()-p.gety())*(q.gety()-p.gety());
int rr=r*r;
if(rr==dis) cout<<"点在圆上"<<endl;
else if(rr<dis) cout<<"点在圆外"<<endl;
else cout<<"点在圆内"<<endl;
}
可以看到在函数名前面申明了对象的来源
对象的初始化和清理
-
构造函数:主要作用在于创建对象时为对象的成员属性赋值,构造函数由编译器自动调用,无须手动调用。
初始化操作,调用这对象数时候默认执行一次 -
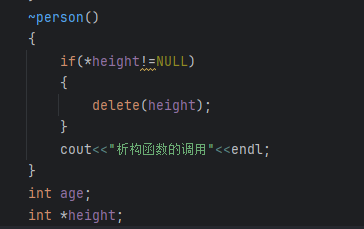
析构函数:主要作用在于对象****销毁前系统自动调用,执行一些清理工作。
清理操作,对象使用完毕,函数结束默认执行一次
这两函数如果不写是默认为空。class person { public: person() { cout<<"person构造函数的调用"<<endl; } ~person() { cout<<"person析构函数的调用"<<endl; } }; void test1() { person p; cout<<"函数要执行要完了"<<endl; }
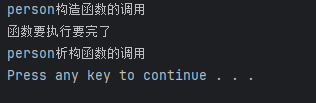
从输出结果可以出,person的析构函数实在test1()马上结束之前才执行,释放这个对象
构造函数的分类和调用
构造函数分为 有参构造和无参构造 按找有无参数划分
还有拷贝构造和普通构造 除了拷贝构造之外都是普通构造
拷贝构造函数不要写错,这里是地址传递,而且拷贝过程不能修改原来的对象内容,所以前面要加const
class person
{
public:
person()
{
cout<<"无参构造函数的调用"<<endl;
}
person(int a)
{
age=a;
cout<<"有参构造函数的调用"<<endl;
}
person(const person &p)
{
age=p.age;
cout<<"拷贝函数的调用"<<endl;
}
int age;
~person()
{
cout<<"析构函数的调用"<<endl;
}
};
如果写了 person() 编译器会认为这是一个函数声明; 类似void task()
不要利用拷贝函数构造初始化对象
//括号法
person p1;
person p2(10);
person p3=person(p2);
这里person(10)是先创建了一个匿名对象,匿名对象在这一行执行完之后马上就会被回收,执行析构函数
//显式法
person p1;
person p2=person(10);
person p3=person(p2);
这里可以看作int,
//隐式法
person p2=10;
person p3=p2;
拷贝函数的调用时机
-
用一个创建好的对象来初始化一个新对象
void test1() { person p1(10); person p2(p1); person p3=p1; }

- 以值传递的方式来给函数传值
void temp(person p)
{
}
void test2()
{
person p;
temp(p);
}
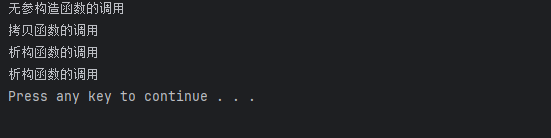
-
以函数返回值的形式返回局部对象
person temp2() { person p(20); cout<<"temp2内的p值为 "<<p.age<<endl; cout<<"temp2内的p地址为 "<<(int *)&p<<endl; return p; } void test3() { person p=temp2(); cout<<"test3内的p值为 "<<p.age<<endl; cout<<"test3内的p地址为 "<<(int *)&p<<endl; }
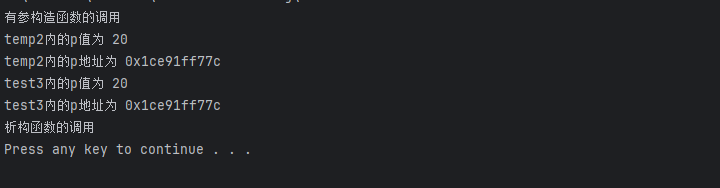
这里和黑马C++的教学视频不一样,那边使用的是VS,VS两个P的地址是不同的,并且调用了两次析构函数。
构造函数的调用规则
默认情况下,C++会给一个类3个默认函数
- 默认无参构造函数
- 默认析构函数
- 默认拷贝函数
构造函数的调用规则很简单,写了有参构造函数,则不会生成默认无参函数
写了拷贝构造函数,有参构造和无参构造都不会生成
深拷贝与浅拷贝
先简单理解浅拷贝
下面这段代码是使用是没有问题的
class person
{
public:
person()
{
cout<<"无参构造函数的调用"<<endl;
}
person(int a)
{
cout<<"有参构造函数的调用"<<endl;
age=a;
}
~person()
{
cout<<"析构函数的调用"<<endl;
}
int age;
};
void test()
{
person p1(10);
person p2(p1);
cout<<p2.age<<endl;
}
int main()
{
test();
system("pause");
return 0;
}
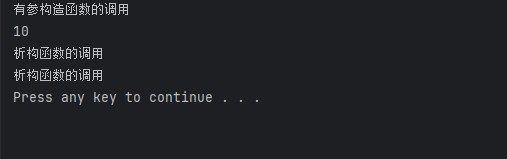
但是如果我我在类里面定义了一个指针
再执行这段代码时
void test()
{
person p1(10,175);
person p2(p1);
cout<<p2.age<<endl;
cout<<*p2.height<<endl;
cout<<"p1的height地址"<<(long long)p1.height<<endl;
cout<<"p2的height地址"<<(long long)p2.height<<endl;
}
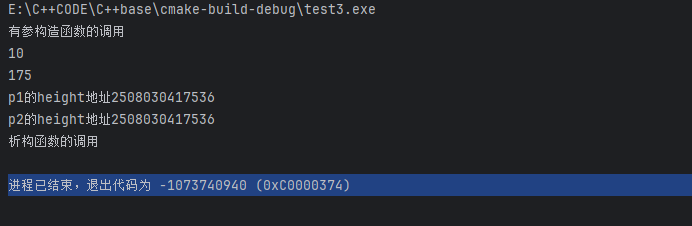
很明显少执行了一个析构函数 并且错误退出
这是因为我们已经使用delete释放p2.height的地址,p1析构函数的调用又去释放一遍所以报错。
这就是浅拷贝。简单的将p1.height的地址原封不动的给了p2.height。
test执行在栈区,是先进先出所以p2的析构函数先执行,再执行p1
回顾:new创建的对象生成在堆区,需要程序员手动释放,所以要使用delete
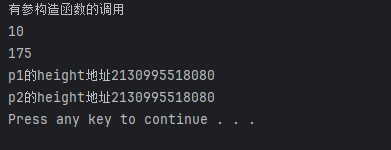
如果我使用默认析构函数会怎么样?
显然,默认构造函数执行成功 😄 编译器默认拷贝构造函数是深拷贝
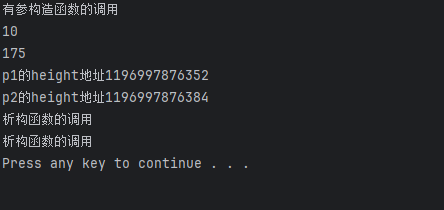
这个问题应该怎么样解决? 很简单,自己写一个深拷贝的拷贝构造函数
person(const person &p)
{
age=p.age;
height=new int(*p.height);
}
执行成功,p1和p2的地址也不一样
初始化列表
给对象一些初始化默认属性 注意写法就好
这种写法直接person p;直接给a,b,c赋默认数值;
class person
{
public:
person():a(10),b(20),c(30)
{
}
int a,b,c;
};
这种写法是要写出person p(10,20,30),直接person p会报错,因为写了有参构造函数,就不会有默认构造函数
class person
{
public:
person(int aa,int bb,int cc):a(aa),b(bb),c(cc)
{
}
int a,b,c;
};
如果我又想要有person p,这种默认有参数又能person p(10,20,30)这样初始化对象该怎么办?
回顾之前函数默认值
- 给函数参数提供默认值
class person
{
public:
person(int aa=10,int bb=20,int cc=30):a(aa),b(bb),c(cc)
{
}
int a,b,c;
};
- 再多写个默认构造参数
class person
{
public:
person()
{
a=10,b=20,c=30;
}
person(int aa,int bb,int cc):a(aa),b(bb),c(cc)
{
}
int a,b,c;
};
类对象作为类成员
C++类中的成员可以是另一个类的对象,我们称该成员为 对象成员
class phone
{
public:
phone(string n)
{
name=n;
cout<<"phone构造"<<endl;
}
~phone()
{
cout<<"phone析构"<<endl;
}
string name;
};
class person
{
public:
person(string n,string np):name(n),p(np)
{
cout<<"person构造"<<endl;
}
void show()
{
cout<<name<<" "<<p.name<<endl;
}
~person()
{
cout<<"person析构函数"<<endl;
}
string name;
phone p;
};
void test()
{
person man("617","华为");
man.show();
}
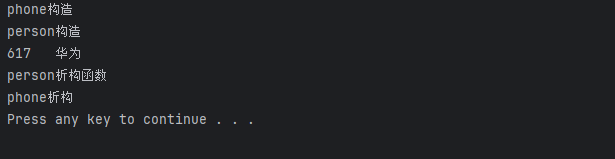
可以看到是 对象成员先构造,再本类构造。析构则是反过来。
静态成员
有两种静态成员变量和静态成员函数
静态成员变量
这个很好理解
可以看到,更改p.a和p2.a的的值都是一样的,说明这两个是其实存的是同一个地方的东西
有3点要注意
- 类内声明 类外初始化
- 所有对象共享同一份数据
- 在编译阶段分配内存??
私有域下的静态成员变量在类外不可访问
class person
{
public:
static int a;
private:
static int b;
};
int person::a=10;
int person::b=20;
void test()
{
person p;
p.a=20;
cout<<p.a<<endl;
person p2;
p2.a=30;
cout<<p.a<<endl;
cout<<p2.a<<endl;
person::a=40;
cout<<person::a<<endl;
}
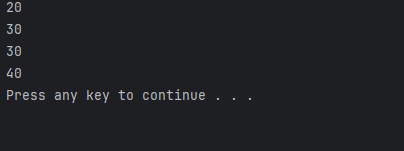
2种访问方式一种直接通过对象访问还有一种通过类名
静态成员函数
静态成员函数只能访问静态成员变量 例如在这里show函数内,是不能访问b的
也有2种访问方式person::show(), 也有private访问权限。
class person
{
public:
static void show()
{
cout<<"正在通过静态成员函数"<<endl;
a=100;
}
static int a;
int b;
};
int person::a=10;
void test()
{
person p;
p.b=20;
cout<<person::a<<endl;
cout<<p.b<<endl;
p.show();
cout<<person::a<<endl;
}
C++对象模型和this指针
空对象占用一个字节 为什么空对象还要占用一个字节的位置呢? 比如说定义2个对象p1,p2,两个都是空的为了区分他们2个所以要占用
可以看到 类里面有个成员函数但是类的大小依旧是int,这就是一个特性
成员变量和成员函数分开存储
静态成员变量也不占用对象空间 只有非静态成员变量才属于类的独享
class person
{
public:
int a;
void show()
{
cout<<a<<endl;
}
};
static int b;
void test()
{
person p;
cout<<sizeof(person)<<endl;
}
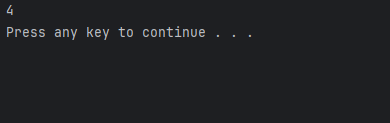
既然成员函数不存放在对象内,那么我们怎么知道是哪一个对象在调用show()函数呢?
C++设计了一个特殊的对象指针,指向被调用的成员函数所属的对象,例如p1调用show()函数,则this指针指向p1。
this指针是隐含每一个非静态成员函数内的一种指针
this指针不需要定义,直接使用即可
这样写会出现报错 很明显,不知道两个a会发生歧义
class person
{
public:
int a;
void seta(int a)
{
a=a;
}
};
- 这样写就OK 当形参和成员变量同名时可以用this指针来区分
class person
{
public:
int a;
void seta(int a)
{
this->a=a;
}
};
- 在类的非静态成员函数中返回对象本身,可使用return *this
这样写没问题,程序正常运行
class person
{
public:
int a;
void seta(int a)
{
this->a=a;
}
void adda(int b)
{
a+=b;
}
};
void test()
{
person p;
p.seta(10);
cout<<p.a<<endl;
p.adda(10);
cout<<p.a<<endl;
}
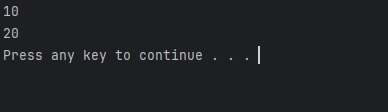
但是如果我们需要重复操作add呢
class person
{
public:
int a;
void seta(int a)
{
this->a=a;
}
person& adda(int b)
{
this->a+=b;
return *this;
}
};
void test()
{
person p;
p.seta(10);
cout<<p.a<<endl;
p.adda(10);
cout<<p.a<<endl;
p.adda(10).adda(10);
cout<<p.a<<endl;
}
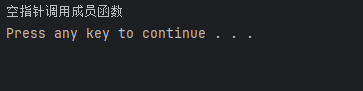
空指针调用成员函数
class person
{
public:
int a;
void show()
{
cout<<"空指针调用成员函数"<<endl;
}
};
void test()
{
person *p=NULL;
p->show();
}
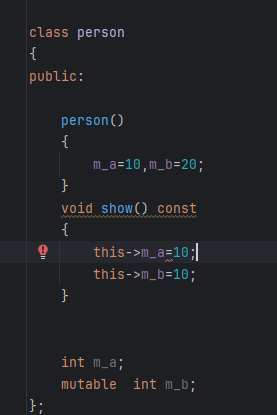
可以看到在成员函数后面加const变成了常函数
常函数不能修改成员属性,可以看到在show函数中,修改m_a这个成员属性出现了报错,但是m_b没有,因为使用了mutable修饰,这样常函数就能修改了
this指针是一个指针常量,指针指向的地址不能修改,类型是 class const,也就是指针的指向不能修改,如果要指针指向的值不可修改需要在指针面前添加 const。 也就是说 const class*const 就是一个指针常量指向地址的值不能修改,也就是const this。 这其实也是指针常量和常量指针的知识*
所以这里的void show() const 主要是因为const没地方写,就写在了函数名后面
常对象,常对象可以访问成员变量,但是不能修改,只能修改加了mutable的成员变量
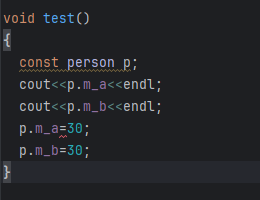
常对象只能调用const成员函数!! 如果show函数后面没加const调用是没效果的
扩展
内存对齐
什么是内存对齐? 很简单的来说就是 书架上放一本书,你最好把这本书挨着别的书放,而不是自己一本书立在那。 每个书架的格子,第一本书都挨着格子,之后书挨着书,这就是内存对齐
为什么要内存对齐? 在64位系统中,CPU一次读取8个字节,一个int是4个字节,现在我有2个int的数据,如果第一个int的起始地址是1,那么我读取这两个字节是:第一个Int 1-4,第二个int是5-8,而CPU读取是0-7一次八个字节,这样存放两个int那么CPU要进行两次读取。 所以内存对齐可以提高CPU访问效率
内存对齐的规则 内存对齐常出现在class和struct中
struct person
{
int a; //4
double c;//8
char c;//1
}
这个结构体的对齐数值通常是里面成员的最大值,8。
结构体的内存布局是按照成员声明的顺序排列的,但编译器会在成员之间插入填充字节(padding),以确保每个成员都对齐到它的对齐值。
例如,这个结构体的对齐值为8, 对齐值是多少,起始地址通常是他的整数倍
成员int,起始地址0,对齐值4,0-3;
padding,填充4个字节4-7
成员double,对齐值8,起始地址8-15;
成员char,对齐值1,起始地址16
总大小16个字节 最后还要保证结构体的总大小是结构体的对齐值的整数倍
指针常量和常量指针
指针常量是指 指针指向不可变,指针指向的地址不能变但是地址的数值可以修改
int* const p; P=NULL不可用 p.data=10可用
常量指针是指 指针指向地址的数值不可以修改,但是指向可以修改
const int* p; p.data=10不可用 p=NULL可用
